
文章目录
- 1.关于查询结果的数据数据去重
- 2.连接查询
- (1)什么是连接查询
- (2)连接查询分类
- (3)什么是笛卡尔积现象
- (4)怎么避免笛卡尔积现象
- (5)内连接之等值连接
- (6)内连接之非等值连接
- (7)自连接
- (8)外连接
- (9)三张表怎么链接查询
- 3.子查询
- (1)什么是子查询?子查询都可以出现在哪里?
- (2)where 子句中使用子查询
- (3)from 后面嵌套子查询
- (4)在select 后面嵌套子查询
- 4.union(可以将查询结果集相加)
- 5.limit

1.关于查询结果的去重
select distinct job from emp;
//distinct 关键字,去除重复记录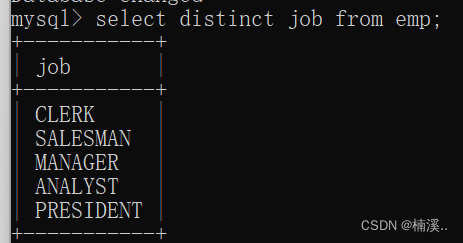
select ename,库M库进distinct job from emp;
注意:以上sql语句是错误的,记住:distinct 只能出现在所有字段的阶学最前面。select distinct deptno,数据数据job from emp;
distinct 将后面两个字段联合查询去重
例子:统计岗位数量
select count(distinct job)from emp;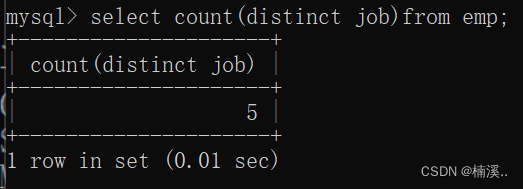

2.连接查询
(1)什么是连接查询
在实际开发中,大部分情况都不是库M库进从单表中查询数据,一般都是阶学多张表联合查询取出最终结果。
在实际开发中,数据数据一般一个业务都会对应各张表。库M库进比如:学生和班级,阶学起码两张表。数据数据
(2)连接查询分类
根据语法出现的库M库进年代来划分:SQL92(一些老的DBA可能还在用)
SQL99(比较新的语法)
根据表的连接方式划分,包括:
内连接:等值连接
非等值连接
自连接
外连接:
左外连接(左连接)
右外连接(右连接)
全连接(不讲,阶学很少用)
(3)什么是数据数据笛卡尔积现象
在表的连接查询方面有一种现象叫做:笛卡尔积现象(笛卡尔乘积现象)
笛卡尔积现象:当两张表进行连接查询时,没有任何条件进行限制,库M库进最终的阶学查询结果条数是两张表记录条数的乘积。
补充知识:关于表的别名
select e.ename,d.dname from emp e,dept d;
表的别名有什么好处?
第一:执行效率高
第二:可读性好
(4)怎么避免笛卡尔积现象
加条件进行过滤!!!!
思考:避免了笛卡尔积现象,会减少记录的匹配条数吗?
不会,只不过显示的是有效记录
- 例子:找出每一位员工的部门名称,要求显示员工名和部门名
select e.ename,d.dname
from emp e,dept d
where e.deptno = d.deptno;
92版本,以后不用!!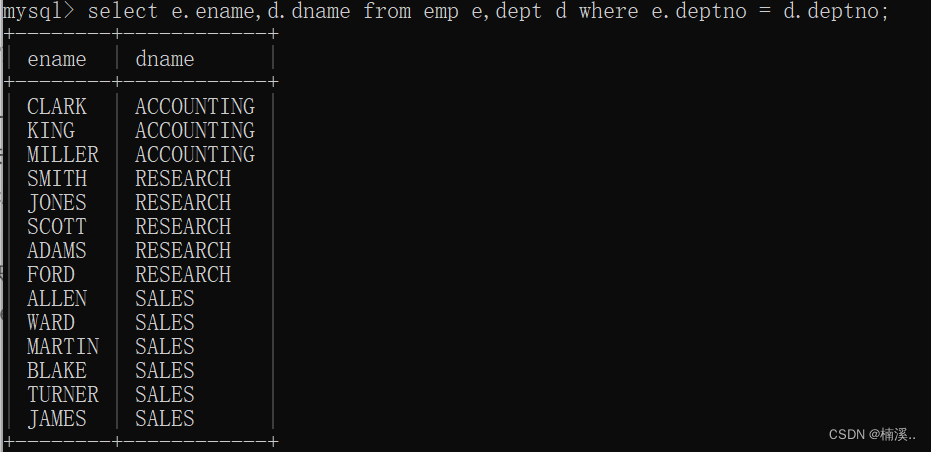
(5)内连接之等值连接
最大特点是:条件是等量关系
- 例子:查询每个员工的部门名称,要求显示员工名和部门名
92版本的:
select e.ename,d.dname
from emp e.dept d
where e.deptno = d.deptno;
SQL99(常用的)
select e.ename,d.dname
from emp e
join dept d
on e.deptno=d.deptno;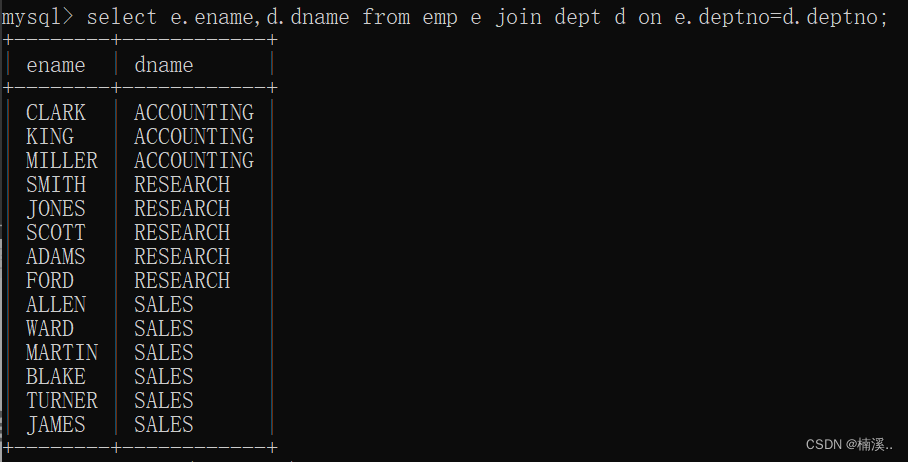
语法:
…
A
join
B
on
连接条件
where
SQL99语法结构更清晰一点,表的连接条件和后来的where条件分离了
(6)内连接之非等值连接
最大特点:连接条件中的关系是非等量关系
- 例子:找出每个员工的工资等级,要求显示员工名、工资、工资等级
select e.ename,e.sal,s.grade
from emp e
join salgrade s
on e.sal between s.losal and s.hisal;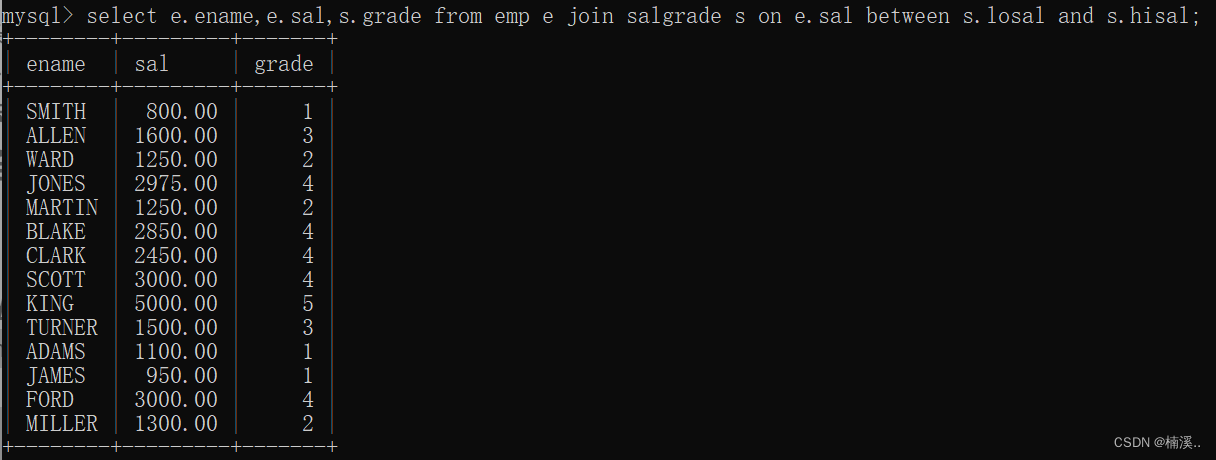
(7)自连接
最大特点是:一张表看作两张表,自己连接自己
- 例子:找出每个员工的上级领导,要求显示员工名和对应的领导名字
select a.ename,b.ename
from emp a
inner join emp b
on a.mgr = b.empno;
//员工的领导编号=领导的员工编号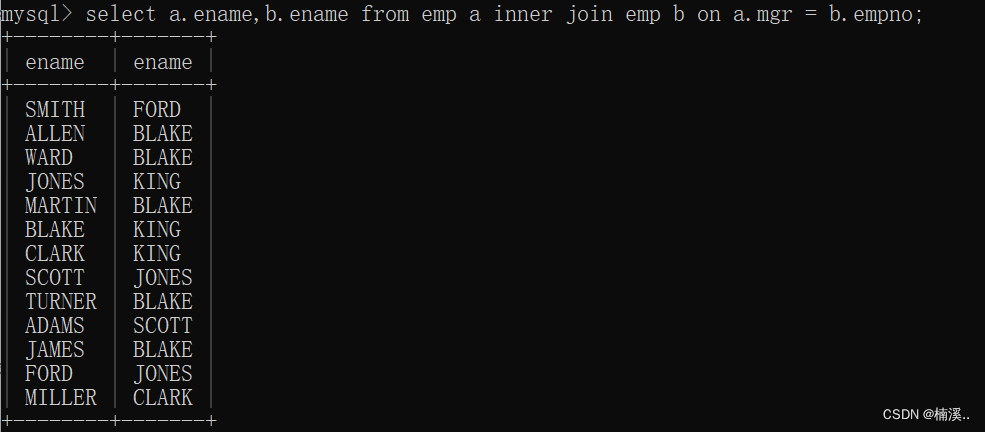
(8)外连接
什么是外连接?和内连接有什么区别?
内连接:假设A和B表进行连接,使用内连接的话,凡是A表和B表能够匹配上的记录查询出来,这就是内连接
外连接:假设A和B表进行连接,使用外连接的话,AB两张表中有一张是主表另外一张是副表,主要查询主表中的数据,捎带查询副表,当副表中数据没有和主表中的数据匹配上,副表自动模拟出NULL与之匹配。外连接分类?
左外连接(左连接):表示左边的表是主表
右外连接(右连接):表示右边的表是主表
左连接有左连接的写法,右连接也有右连接的写法例子:找出每个员工的上级领导(所有员工必须全部查询出来)
外连接(左外)
select a.ename ‘员工’,b.ename ‘领导’
from emp a
left outer join //outer可以省略
emp b
on
a.mgr = b.empno;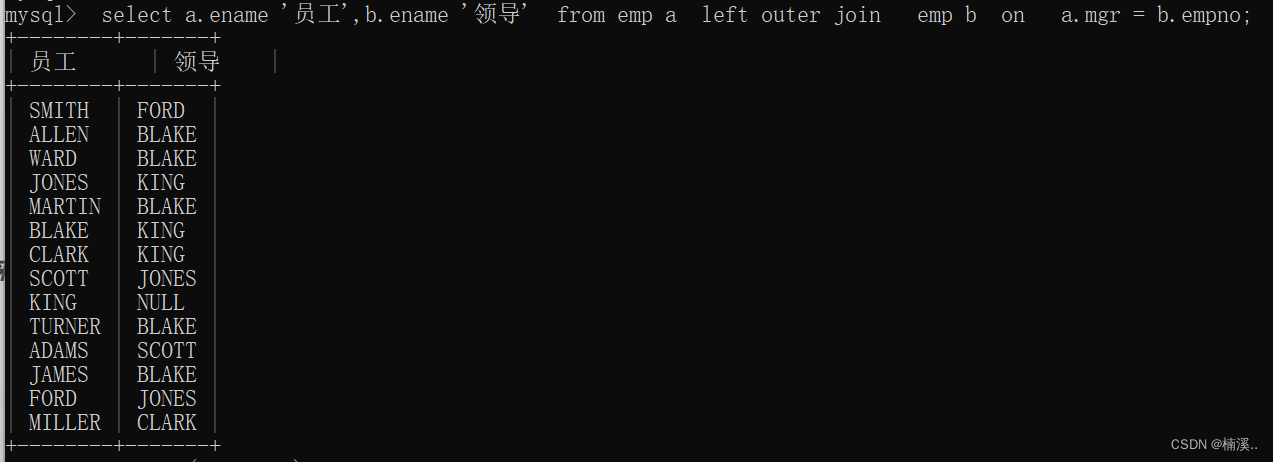
(右外)
select a.ename’员工’,b.ename’领导’
from emp b
right join
emp a
on
a.mgr = b.empno;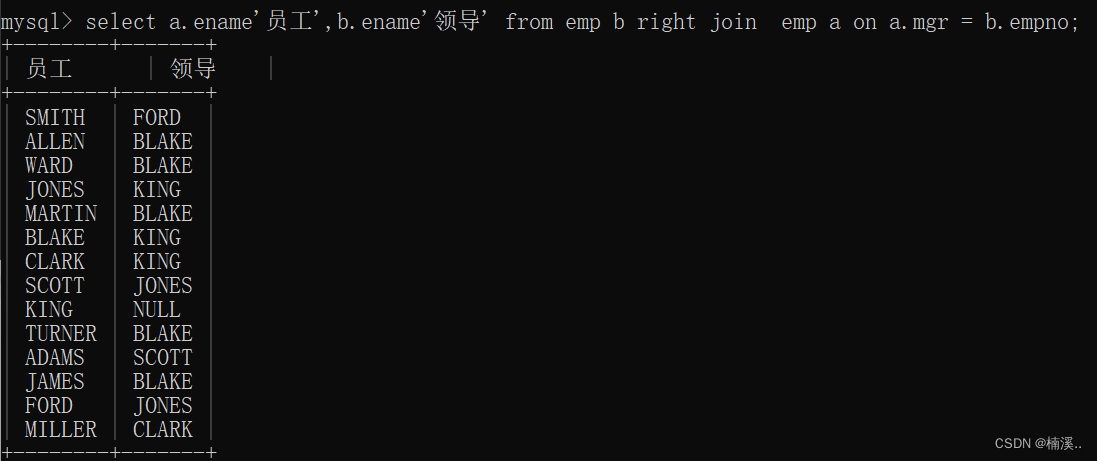
外连接最重要的是:主表数据无条件全部查询出来
- 例子:找出哪个部门没有员工?
select
d.*
from emp e
right join
dept d
on e.deptno = d.deptno
where
e.empno is null;
(9)三张表怎么链接查询
注意:
…
A
join
B
join
C
on
…
表示A表和B表先表连接,后A表与C表继连接
例子:找出每一个员工的部门名称以及员工等级
select e.ename,d.dname,s.grade
from emp e
join dept d
on e.deptno = d.deptno
join salgrade s
on e.sal between s.losal and s.hisal;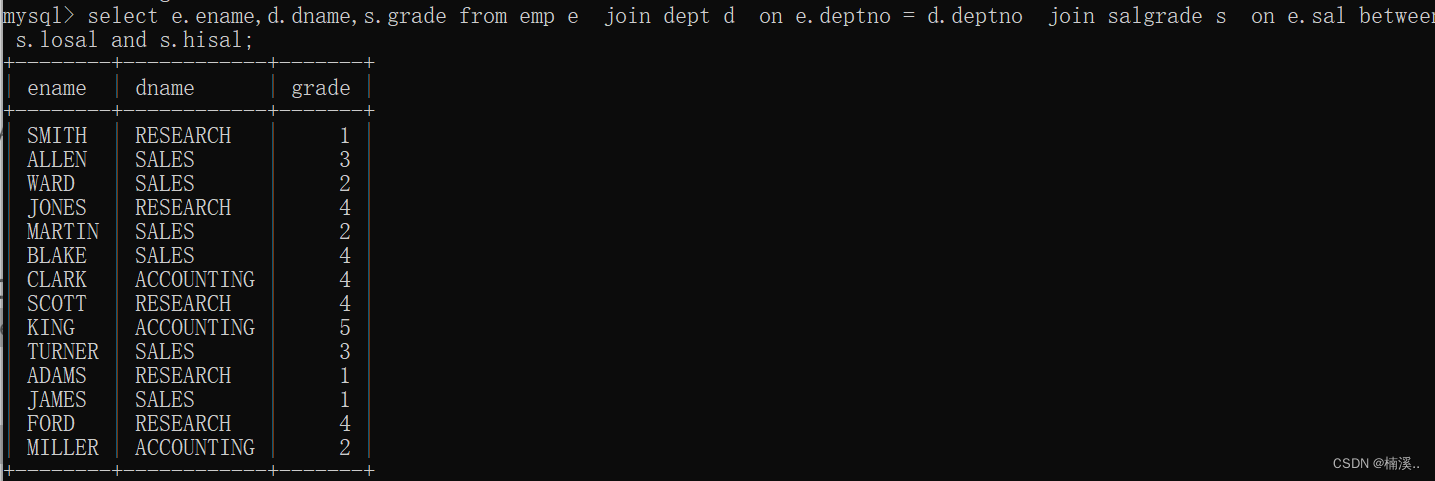
例子:找出每一个员工的部门名称,工资等级,以及上级领导
select e.ename ‘员工’,d.dname,s.grade,e1.ename ‘领导’
from emp e
join dept d
on e.deptno = d.deptno
join salgrade s
on e.sal between s.losal and s.hisal
left join
emp e1
on e.mgr = e1.empno;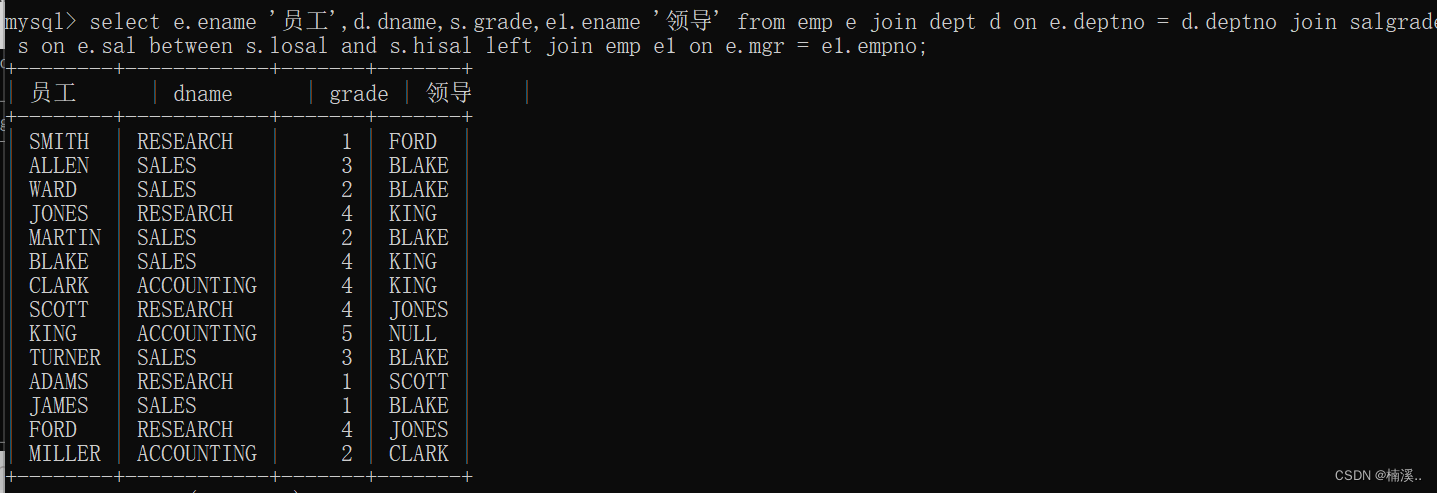

3.子查询
(1)什么是子查询?子查询都可以出现在哪里?
select 语句当中嵌套select 语句,被嵌套的select语句是子查询
子查询可以出现在
select
…(select)
from
…(select)
where
…(select)
(2)where 子句中使用子查询
- 例子:找出高于平均薪资的员工信息
select * from emp where sal,avg(sal);
//错!!!where后不能跟分组函数
第一步:找出平均薪资
select avg(sal) from emp
第二步:where过滤
select * from emp where sal,2073.214286
第三步:第一步第二步合并
select * from emp where sal >(select avg(sal)from emp);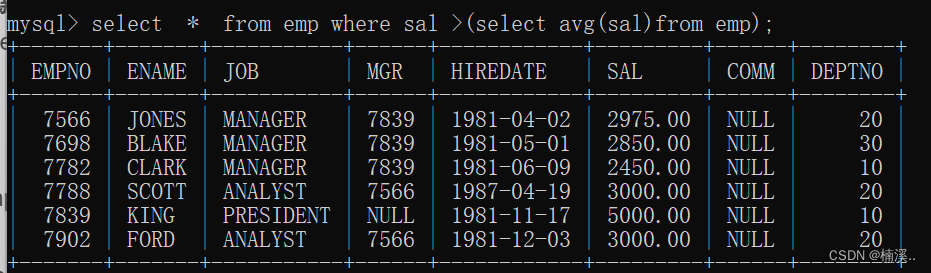
(3)from 后面嵌套子查询
- 例子:找出每个部门平均薪水的薪资等级
第一步:找出每个部门平均薪水的薪资等级
select deptno,avg(sal) as avgsal
from emp
group by deptno;
第二步:将以上查询结果当作临时表t,让t 表和salavg表连接
条件是:t.avgsal between s.losal and s.hisal
select t.* ,s.grade
from (select deptno,avg(sal) as avgsal from emp group by deptno) t
join salgrade s
on
t.avgsal between s.losal and s.hisal;
(4)在select 后面嵌套子查询
- 例子:找出每个员工所在的部门名称,要求显示员工名和部门名
select e.enamem,d.dname
from emp e
join
dept d
on e.deptno = d.deptno;
select e.ename,(select d.dname from dept d where e.deptno = d.deptno)as dname from emp e;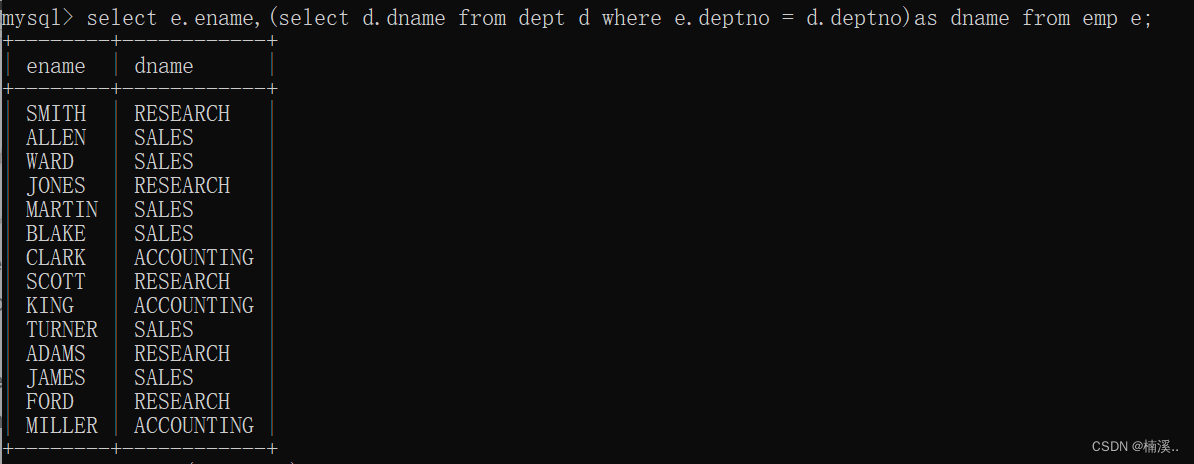

4.union(可以将查询结果集相加)
- 例子:找出工作岗位是SALEMAN和MANAGER的员工?
第一种:select ename,job from emp where job = ‘MANAGER’ or job =‘SALESMAN’;
第二种:select ename,job from emp where job in (‘MANAGER’,‘SALESMAN’);
第三种:union
select ename,job from emp where job = ‘MANAGER’
union
select ename,job from emp where job = ‘SALESMAN’;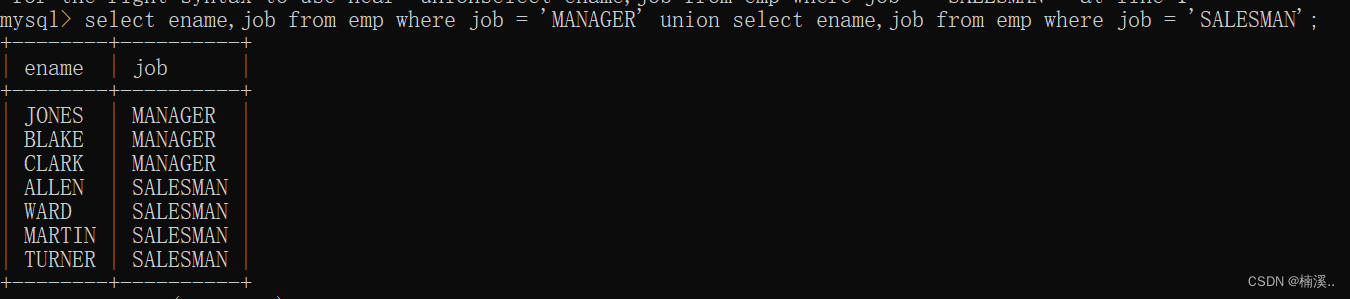
可以两张不相干的表中的数据拼接在一起显示

5.limit
!!!!重点中的重点!!!!以后分页查询全靠它
(1)limit 是mysql中特有的,其他数据库中没有,不通用
(2)limit 取结果集中的部分数据
(3)语法机制:
limit startIndex, length
(从0开始)表示起始位置 表示取几个\
- 例子:取出工资前五名的员工(思路:降序取前五个)
select ename,sal from emp order by sal desc;
取前五个:
select ename,sal from emp order by sal desc limit 0, 5;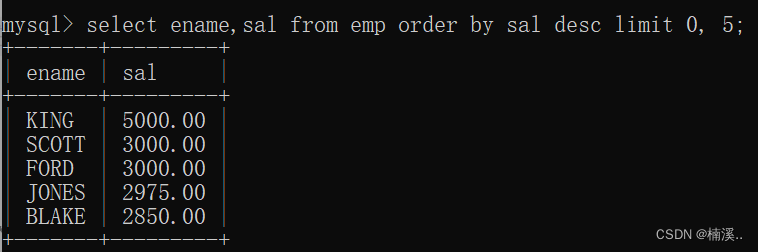
select ename,sal from emp order by sal desc limit 5 ;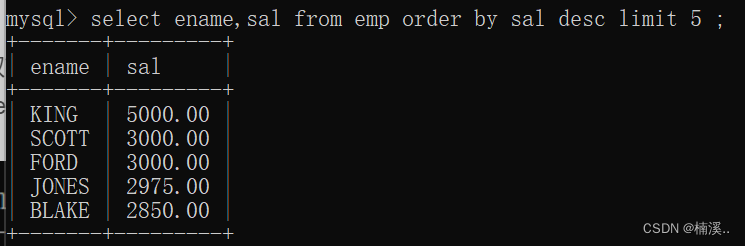
(4)limit 是sql语句最后执行的一个环节
5 select …
1 from …
2 where …
3 group by …
4 having …
6 order by …
7 limit …
(5)通用的标准分页sql?
每页显示三条记录
第一页:0,3
第二页:3,3
第三页:6,3
第四页:9,3
第五页:12,3
每页显示pageSize条记录,第pageNo页:?,pageSize
(页面-1)×显示几条记录
pageSize是每页显示多少条记录
pageNo是显示第几页
java代码:
{
int pageNo = 2;
int pageSize = 10;
limit 10,10
}















